Prerequisite
java SE development kit 1.8 Download
Eclipse IDE for Java EE Developers (Eclipse Kepler) Download
Hadoop 3.1.1 on windows Download
Apache Spark version 1.6.2 Download
JavaCV 1.3.3 binary archive Download
Spark ML Library Version 1.3.0 Download
DL4J nd4j-native-platform 1.0-beta3 version Download
Datasets
Download the given datasets KTH and SIAT from below link
Run Program
Video Annotation
Download SIAT dataset which consists of 20 videos in train and 3 videos in test in each category
Create Train and Test data by moving all train and test data into a single folder respectively
Then rename the video file from 1 to n (number of video, in our case 1 – 60 for training and 1 -9 for testing) and also keep the label as the new video number
Go to siat.vdml.videoAnnotation.App.java class and open it
Give path for Train and test data
Give the path for output file both for train and test feature and also for Spatial annotation final output
Call siat.vdml.videoAnnotation.spatial.App.main(trainDataPath, testDataPath, trainFeature, testFeature) for spatial feature extraction
trainDataPath is the train path location
testDataPath is the test data path location
trainFeature is the output file for spatial feature extraction for train data
testFeature is the output file for spatial feature extraction for test data
Call siat.vdml.videoAnnotation.temporal.App.main(trainDataPath, testDataPath, trainFeature, testFeature) for temporal feature extraction
trainDataPath is the train path location
testDataPath is the test data path location
trainFeature is the output file for temporal feature extraction for train data
testFeature is the output file for temporal feature extraction for test data
Call siat.vdml.videoAnnotation.classification.SearchNearestFrames.classify (trainFeaturePath, testFeaturePath, labelFile) for spatial annotation
trainFeaturePath is the feature path for train data that we got from (g)
testFeaturePath is the feature path for test data that we got from (g)
labelFile is the label file for spatial annotation
Call siat.vdml.videoAnnotation.classification.SearchNearestClips.classify (trainFeaturePath, testFeaturePath) for temporal annotation
trainFeaturePath is the feature path for train data that we got from (h)
testFeaturePath is the feature path for test data that we got from (h)
Human Action Recognition
Download KTH datasets which consist of three categories and in each category consists of 80 and 20 videos as train and test respectively
Create Train and Test data by moving all train and test data into a single folder respectively
Then rename the video file from 1 to n (number of videos, in our case 1 – 240 for training and 1 - 60 for testing)
Open siat.vdml.actionRecognition.App.java class and give the train, test, savePath
Call siat.vdml.actionRecognition.callSpark.featureExtraction(data_url, result_url, trainType) for feature extraction
Data_url is for train/test data path
Result_url is for the feature extraction output file
trainType is true then it’s for training data and false for testing data
Call siat.vdml.actionRecognition.classification.Train_RandomForest.TrainData (data_url, no_class, no_tree, depth, bins)
Data_url is the train feature data got from (e)
no_class is the number of class of the dataset
no_tree is the model parameter, how many tree want for training
depth is the depth of the tree
bin is for number of bin we want for training
Call siat.vdml.actionRecognition.classification.Test_RandomForest.classify(data_url, model)
Data_url is the test feature data path obtain from (e)
Model is the trained model obtain from (f)
APIs
End User
| APIs |
Description |
| siat.vdml.videoAnnotation (video_data, “Method�?) |
Annotate each frame from a video and retrieve true video annotation as tags or sentences |
|
Description |
Data Types |
| Input |
Video Data and Method Name |
Video (avi, Mp4) |
| Output |
Tags as well as Sentence |
String |
| Method |
| distane_Learning |
Nearest Neighbor Search Approach to search nearest frame and clips |
| topic_Model |
Topic modeling is the process of identifying topics in a set of documents |
| Matrix_Completion |
Matrix completion is the task of filling in the missing entries of a partially observed matrix. A wide range of datasets are naturally organized in matrix form |
Developer
Scene Based Feature Extractor
| APIs |
Description |
| siat.vdml.videoAnnotation(video_data) |
Annotate each frame from a video and retrieve true video annotation as tags or sentences |
| siat.vdml.videoAnnotation.sceneBasedFeatureExtractor(AlgoOBJ) |
Extract spatial feature from video by taking individual frame |
|
Description |
Data Types |
| Input |
CNN Algorithm Object |
Object |
| Output |
Feature Vector |
2D Double Array |
| Algorithm |
| VGG19 |
VGG-19, from Very Deep Convolutional Networks for Large-Scale Image Recognition, take fixed size image input as {3, 224, 224} |
| DarkNet19 |
There are 2 pretrained models, one for 224x224 images and one fine-tuned for 448x448 images. Call setInputShape() with either {3, 224, 224} or {3, 448, 448} before initialization |
| ResNet |
Residual networks for deep learning and take input as {3, 224, 224} |
Dynamic Feature Extractor
| APIs |
Description |
| siat.vdml.videoAnnotation(video_data) |
Annotate each frame from a video and retrieve true video annotation as tags or sentences |
| siat.vdml.videoAnnotation.dynamicFeatureExtractor(AlgoOBJ) |
Extract Dynamic Feature from Video |
|
Description |
Data Types |
| Input |
Dynamic Feature Extractor Algorithm Object |
Object |
| Output |
Feature Vector |
Double Array |
| Algorithm |
| VLBP |
Volume Local Binary pattern compare pixel with center pixel |
| VLTP |
Volume Local Ternary Pattern compare pixel with center pixel and return ternary pattern. |
| LBP_TOP |
LBP-TOP is an extension of LBP from two-dimensional space to three-dimensional space including spatial and time domain |
Similarity Measure
| APIs |
Description |
| siat.vdml.videoAnnotation.SearchSimilarFrame (algo Obj) |
Calculate Similarity score for Query Feature and Database Feature and return array tags as output |
| siat.vdml.videoAnnotation.SearchSimilarClips (algo Obj) |
Calculate Similarity score for Query Feature and Database Feature and return sentence as output |
|
Description |
Data Types |
| SearchSimilarFrame |
Input |
Similarity Measure Algorithm Object |
Object |
| Output |
tags |
String Array |
| SearchSimilarClips |
Input |
Similarity Measure Algorithm Object |
Object |
| Output |
Sentence |
String |
| Algorithm |
| distane_Learning |
Nearest Neighbor Search Approach to search nearest frame and clips |
| topic_Model |
Topic modeling is the process of identifying topics in a set of documents |
| Matrix_Completion |
Matrix completion is the task of filling in the missing entries of a partially observed matrix. A wide range of datasets are naturally organized in matrix form |
Admin
Scene Based Feature Extractor
| APIs |
Description |
| siat.vdml.videoAnnotation(video_data) |
Preprocess video as color frame and gray frame |
| siat.vdml.videoAnnotation.sceneBasedFeatureExtractor |
Extract spatial feature from video |
|
Description |
Data Types |
| Input |
Frame |
Frame Data (jpg, png, jpeg) |
| Output |
Feature Vector |
2D Double Array |
| Method |
| VGG19 |
VGG-19, from Very Deep Convolutional Networks for Large-Scale Image Recognition, take fixed size image input as {3, 224, 224} |
| DarkNet19 |
There are 2 pretrained models, one for 224x224 images and one fine-tuned for 448x448 images. Call setInputShape() with either {3, 224, 224} or {3, 448, 448} before initialization |
| ResNet |
Residual networks for deep learning and take input as {3, 224, 224} |
Dynamic Feature Extractor
| APIs |
Description |
| siat.vdml.videoAnnotation(video_data) |
Preprocess video as color frame and gray frame |
| siat.vdml.videoAnnotation.dynamicFeatureExtractor |
Extract Dynamic Feature from Video |
|
Description |
Data Types |
| Input |
Video |
Video(mp4, avi) |
| Output |
Feature Vector |
Double Array |
| Method |
| VLBP |
Volume Local Binary pattern compare pixel with center pixel |
| VLTP |
Volume Local Ternary Pattern compare pixel with center pixel and return ternary pattern |
| LBP_TOP |
LBP-TOP is an extension of LBP from two-dimensional space to three-dimensional space including spatial and time domain |
Similarity Measure
| APIs |
Description |
| siat.vdml.videoAnnotation.SearchSimilarFrame |
Calculate Similarity score for Query Feature and Database Feature |
| siat.vdml.videoAnnotation.SearchSimilarClips |
Calculate Similarity score for Query Feature and Database Feature |
|
Description |
Data Types |
| SearchSimilarFrame |
Input |
Query_feature, Database_feature |
Text file |
| Output |
Array of Frame ID |
Integer Array |
| SearchSimilarClips |
Input |
Query_feature, Database_feature |
Text file |
| Output |
Clip ID |
Integer |
| Method |
| distane_Learning |
Nearest Neighbor Search Approach to search nearest frame and clips |
| topic_Model |
Topic modeling is the process of identifying topics in a set of documents |
| Matrix_Completion |
Matrix completion is the task of filling in the missing entries of a partially observed matrix. A wide range of datasets are naturally organized in matrix form |
Retrieve Tags
| APIs |
Description |
| siat.vdml.videoAnnotation.retrieveTagsForFrame |
Retrieve tags from given ID |
| siat.vdml.videoAnnotation.retrieveTagsForClip |
Retrieve sentence from given ID |
|
Description |
Data Types |
| retrieveFrame |
Input |
Array of Frame ID |
Integer Array |
| Output |
Tags |
String Array |
| retrieveClip |
Input |
Frame ID |
Integer |
| Output |
Sentence |
String |
Upload Files
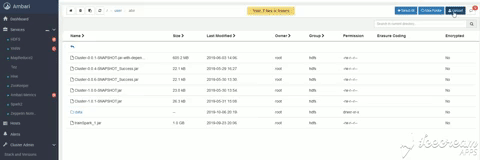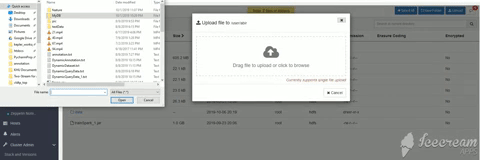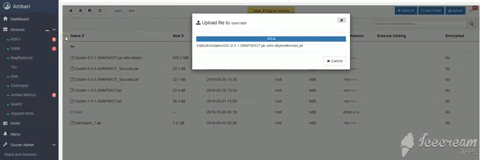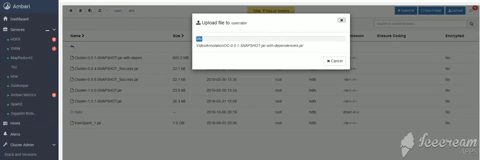
Upload Jar File
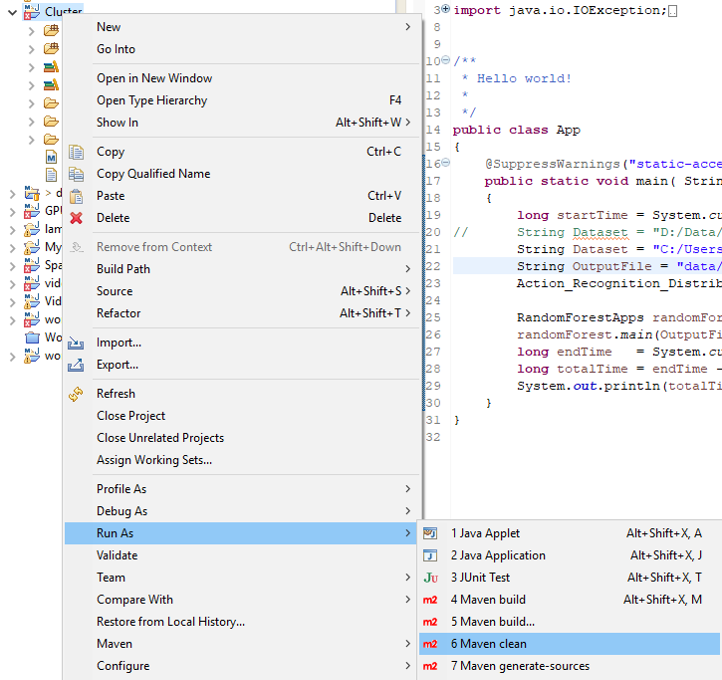
Go to cluster and Create a Directory as Jar
Upload jar file on that directory
Upload Videos
Go to cluster and Create directory as Train and test
Upload training and testing videos on Train and test directory respectively