Introduction
We introduce and develop a spatiotemporal-based distributed video annotation platform. Our works provide both visual information (spatial information) and spatiotemporal (semantic) information. We divide our work into two parts: spatial annotation and spatiotemporal annotation. Each part further divided into three parts: preprocessing, feature extraction, and tag retrieval. For feature extraction, we introduced a spatiotemporal descriptor, namely, volume local directional ternary pattern-three orthogonal planes (VLDTP-TOP). Furthermore, we developed the distributed version of the existing state-of-the-art algorithms: LBP, LTP, and LDTP for the spatial feature extraction, and MBP, VLBP, and LBP-TOP for the temporal feature extraction. We employed open-source Apache Spark to distribute the feature extraction algorithms to make the platform scalable, faster, and fault-tolerant. In addition, we provide video annotation APIs for the developer. Since in this work, we propose a spatiotemporal-based video annotation platform, we required a new video dataset that contained spatial and temporal ground truth tags. Therefore, we introduce a new video dataset, the SpatioTemporal Video Annotation Dataset (STAD). Experimental analysis was conducted on STAD, which showed the excellence of our proposed approach.
The main contributions of this work are:
- We introduce a new distributed spatiotemporal-based video annotation platform that provides visual information and spatiotemporal information of a video.
- We propose a spatiotemporal feature descriptor named volume local directional ternary pattern-three orthogonal planes (VLDTP-TOP) on top of Spark.
- We developed several state-of-the-art appearance and spatiotemporal-based video annotation APIs for the developer and video annotation services for the end-users.
- We propose a video dataset that supports both spatial and spatiotemporal ground truth.
Video Annotation Platform
The architecture for the proposed distributed video annotation is presented in Figure 1 and consists of mainly four layers, the big data storage layer (BDSL), the distributed video data processing layer (DVDPL), the distributed video data mining layer (DVDML), and the video annotation services layer (VASL) respectively. Furthermore, the framework was designed for three basic users according to their roles: end-users, developers, and administrators. The end-users use this platform for their application-oriented solution. In contrast, APIs are developed for the developer so that a developer can produce customized applications. The proposed platform provides algorithm-as-a-service(AaaS) for the developer so that they can develop annotation services and algorithms. The administrator is responsible for providing services to the end-users and video annotation APIs to the developer. Moreover, the administrator manages the platform and the services.
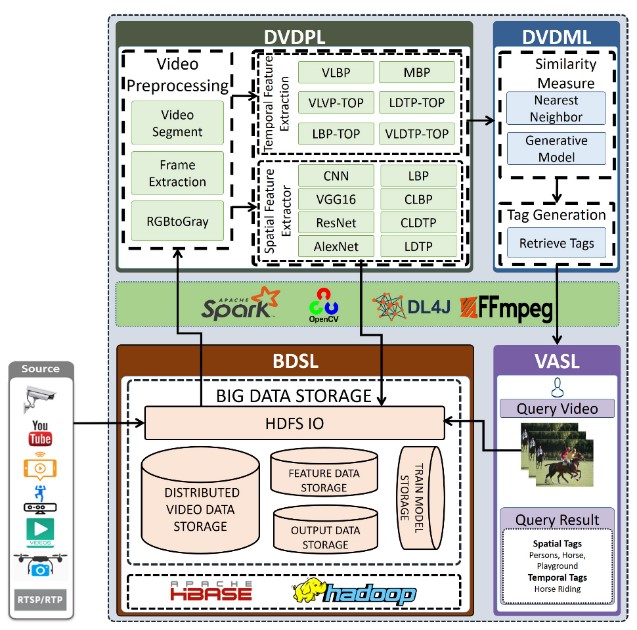
Figure 1. Architecture of the proposed distributed spatiotemporal video annotation platform.
We have developed several state-of-the-art algorithms for both spatial and spatiotemporal feature descriptors. We implemented the existing LBP, and CNN model (e.g., VGGNet) on top of Spark in order to support distributed processing. Moreover, we introduced three-channel-based color LDTP. Similarly, we also developed the existing VLBP, and MBP for capturing spatiotemporal features. Furthermore, we also proposed the local directional ternary pattern-three orthogonal planes (LDTP-TOP) and the volume local directional ternary pattern-three orthogonal planes (VLDTP-TOP) for obtaining the spatiotemporal information. Our proposed descriptors show better precision than the existing algorithms.
Big Data Storage Layer
The big data storage layer (BDSL) provides APIs to store data required for video annotation. The BDSL was created using Open-Source Hadoop HDFS which provides distributed data storage for different types of files. In our work we divided BDSL into five sub-parts: HDFS input/output (HDFS IO), distributed video data storage (DVDS), feature data storage (FDS), output data storage (ODS), and trained model storage (TMS).
Distributed Video Data Processing Layer (DVDPL)
The key part of the proposed architecture is the video data processing layer, wherein video data are processed in a distributed manner and intermediate feature data for the video data mining layer is returned. The main reason for distributed processing is to increase the performance and latency concerning the time that it takes for processing. Since the video data processing layer takes the more time than the other layer, we performed distributed processing in the DVDPL. Open-source distributed framework Apache Spark was utilized for distributed processing. Apache Spark provides a distributed in-memory based framework for data labels. However, they do not have any native support for video data. Furthermore, Spark does not provide any higher-level APIs for video processing. Existing literature for video annotation does not provide distributed services and only considers spatial information and ignores the most significant temporal information from a video. However, temporal information is required to find the superior knowledge.
Distributed Video Data Mining Layer (DVDML)
The distributed video data mining layer (DVDML) is responsible for assigning tags by measuring the similarity using the nearest neighbor algorithm, which takes the trained model and test features as input. The test feature comes from the previous layer and the trained model retrieves from HDFS through the HDFS IO unit. Finally, the output is stored in HDFS as a JSON, CSV, or text file.
Video Annotation Service Layer (VASL)
The video annotation service layer is used to interact with the system using a Web interface. End-users provide the query video to the system and get the desired output through the video annotation service layer (VASL). The developer can use APIs from different layers using the VASL layer.
Video Annotation APIs
We have developed video annotation APIs for the developer so that they can develop video annotation services. We have four main categories for video annotation APIs: preprocessing, spatial feature extraction, dynamic feature extraction, and similarity measure APIs.
Spatiotemporal Based Video Annotation
Figure 2 illustrates the end-to-end flow of our proposed spatiotemporal-based video annotation platform. The proposed platform is divided into two main parts: spatial video annotation (SVA) and spatiotemporal video annotation (STVA). SVA is responsible for retrieving spatial information from each frame of a video, which is similar to existing video annotation works. In the literature, video annotation detects objects from each frame of a video and annotate the object information. However, it ignores the true video information that comes with respect to time. Thus, our works proposed a spatiotemporal-based video annotation to solve this issue. Both parts are further divided into three sub-parts: a feature extractor, a similarity measure, and an annotator.
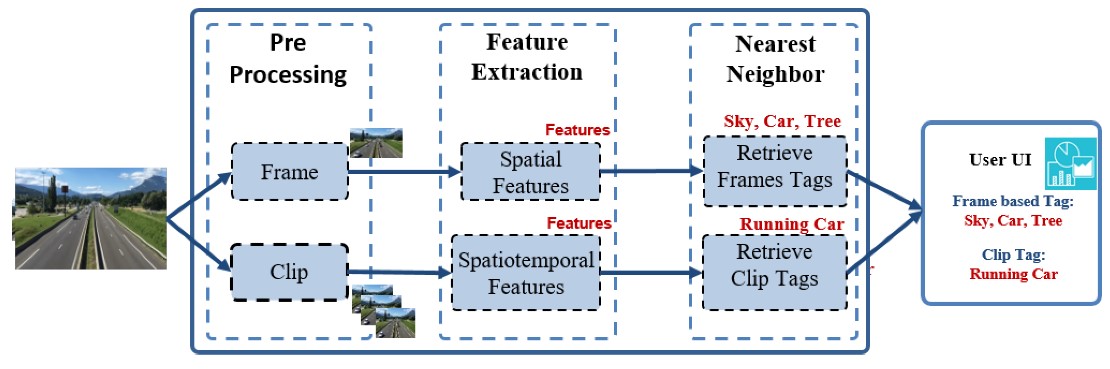
Figure 2. End-to-end flow diagram of the proposed spatiotemporal-based video annotation platform.
SpatiotemporalLocal Directional Ternary Pattern-Three Orthogonal Plane (LDTP-TOP)
LBP-TOP can capture the dynamic features from the video data; however, it suffers from noise and is sensitive to lighting illumination as it uses LBP for its computation. In order to overcome the issues of LBP-TOP, we proposed a new descriptor, namely, local directional ternary pattern-three orthogonal plane (LDTP-TOP), which includes shape, texture, and motion information. LDTP captures the spatial features that are used for texture analysis and we adopt LDTP for the temporal feature extraction by using three orthogonal planes, XY, XT, and YT.
Spatiotemporal Local Directional Ternary Pattern (VLDTP)
However, by applying the LDTP-TOP, we may still lose some information, since it takes 18 pixels into account during the computation from 27 pixels of the three consecutive frames, e.g., it ignores 8 pixels of information from the previous and next frame. Furthermore, in the LDTP-TOP computation, several pixels are used multiple times, which brings in a redundancy issue. In order to resolve this problem, we introduce the volume local directional ternary pattern (VLDTP).
Volume Local Directional Ternary Pattern-Three Orthogonal Plane (VLDTP-TOP)
Afterward, we compute the volume local directional ternary pattern-three orthogonal planes (VLDTP-TOP) by using a concatenated fusion of LDTP-TOP and VLDTP. Since we solve the LBP-TOP issues using LDTP-TOP and LDTP-TOP issues using VLDTP, the proposed VLDTP-TOP leads to better accuracy. On the other hand, feature extraction is the most time-consuming and complex part of our proposed framework; therefore, to enhance and boost the performance of our proposed approach we use Apache Spark to distribute feature extraction part that leads to faster processing and better throughput.
STAD Dataset
Existing video datasets consider either spatial or temporal information. However, there are no datasets available that provide both. Due to the lack of a spatiotemporal video dataset for video annotation domain that contains ground truth information both for spatial and temporal information, we proposed a novel spatiotemporal video dataset STAD which includes diverse categories, as depicted in Figure 10. STAD consists of 11 dynamic and 20 appearance categories. Among dynamic categories, there are four main categories: human action, emergency, traffic, and nature. We divide human action into two subcategories: single movement and crowd movement. The STAD dataset is the combination of UCF101 [53], Dynamic texture DB [54], and a subset of YouTube 8M. The details of our proposed STAD dataset are given in Table 1.
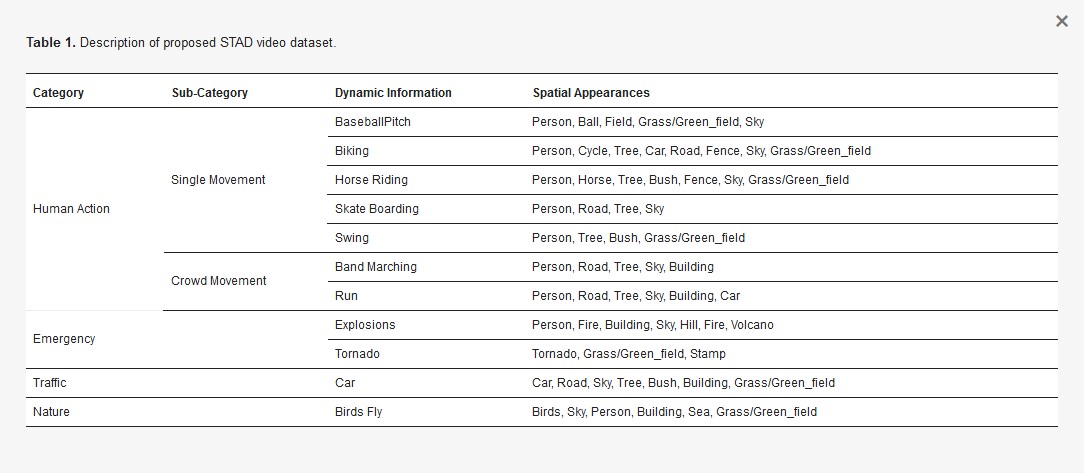
Experimental Analysis
VolumeScalability and Throughput testing
Scalability and throughput has been tested on the proposed STAD dataset.
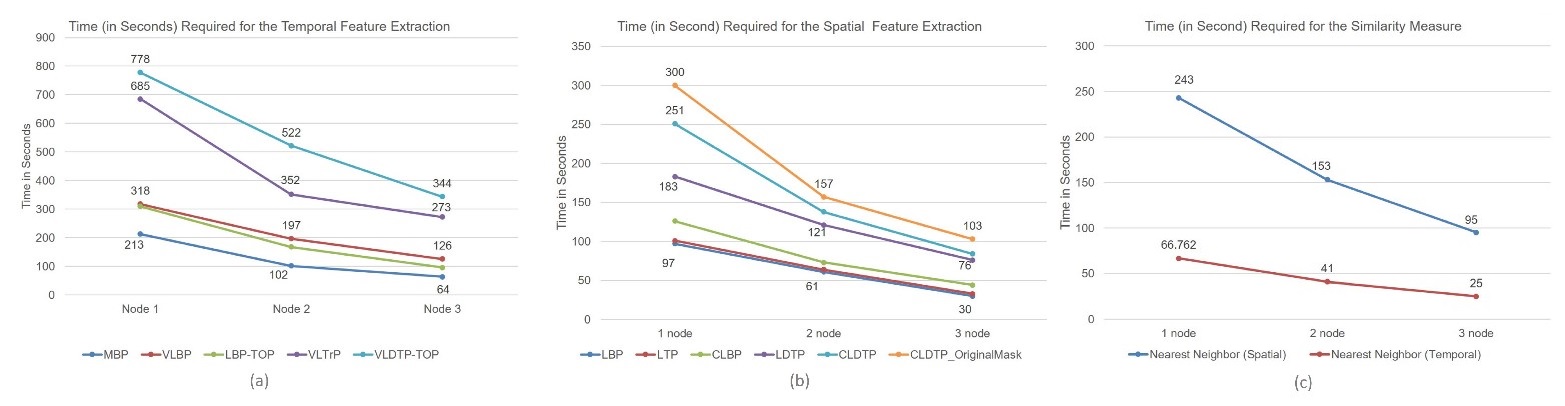
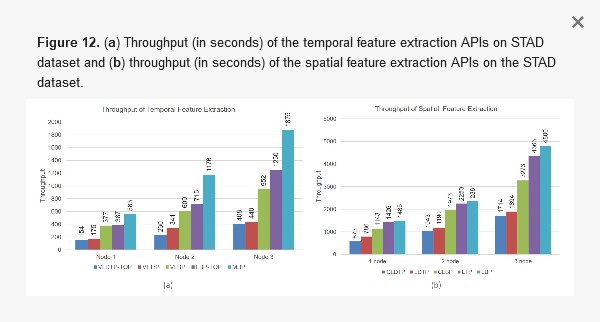
Extensive experiments have done on different dataset as well as with different state-of-the-art algorithms with our proposed work. Figure shows the details of the expreiments.
Papers
Islam, M.A.; Uddin, M.A.; Lee, Y.-K. A Distributed Automatic Video Annotation Platform. Appl. Sci. 2020, 10, 5319.