Introduction
It has been reported that the data generated by various Internet of things (IoT) devices will see a growth rate of 28.7% over the period 2018-2025, where surveillance videos are the majority shareholder, i.e., 65%. Such an enormous video data is considered as "video big data" because a variety of sources generate a large volume of video data at high velocity that holds high value. Video data are acquired directly from real-world domains and meet the veracity characteristic. Handling large-scale complex video data is not worthwhile utilizing conventional data analysis approaches. Video big data pose challenges for video management, processing, mining, and manipulation. Therefore, more comprehensive and sophisticated solutions are required to manage and analyze large-scale unstructured video data. Furthermore, due to the large volume of video data, it requires a flexible solution to store and mine for possible decision-making. However, large-scale Intelligent Video Analytics (IVA) becomes a reality on the rise of big data analytics and cloud computing technologies.
The focus of existing studies is more on video analytics (value extraction) and overlook the data curation issues encompassing value, volume, velocity, and variety management throughout the lifecycle of IVA in the cloud. Data curation is the active management of data over its life cycle, from creation, acquisition, and initial storage to the time when it is archived or becomes obsolete. The IVA lifecycle in the cloud spin around IVA approaches. The existing solutions also do not consider factors like the management of high-level and low-level features while deploying IVA algorithms. Motivated by such limitations, we propose and implement a comprehensive intermediate results orchestration based service-oriented data curation framework for large-scale online and offline IVA in the cloud known as BDCL. BDCL is the foundation layer of SIAT architecture. SIAT is a layered architecture for distributed IVA in the cloud, as shown in Figure 1. BDCL is the base layer that allows the other layers to develop IVA algorithms and services.
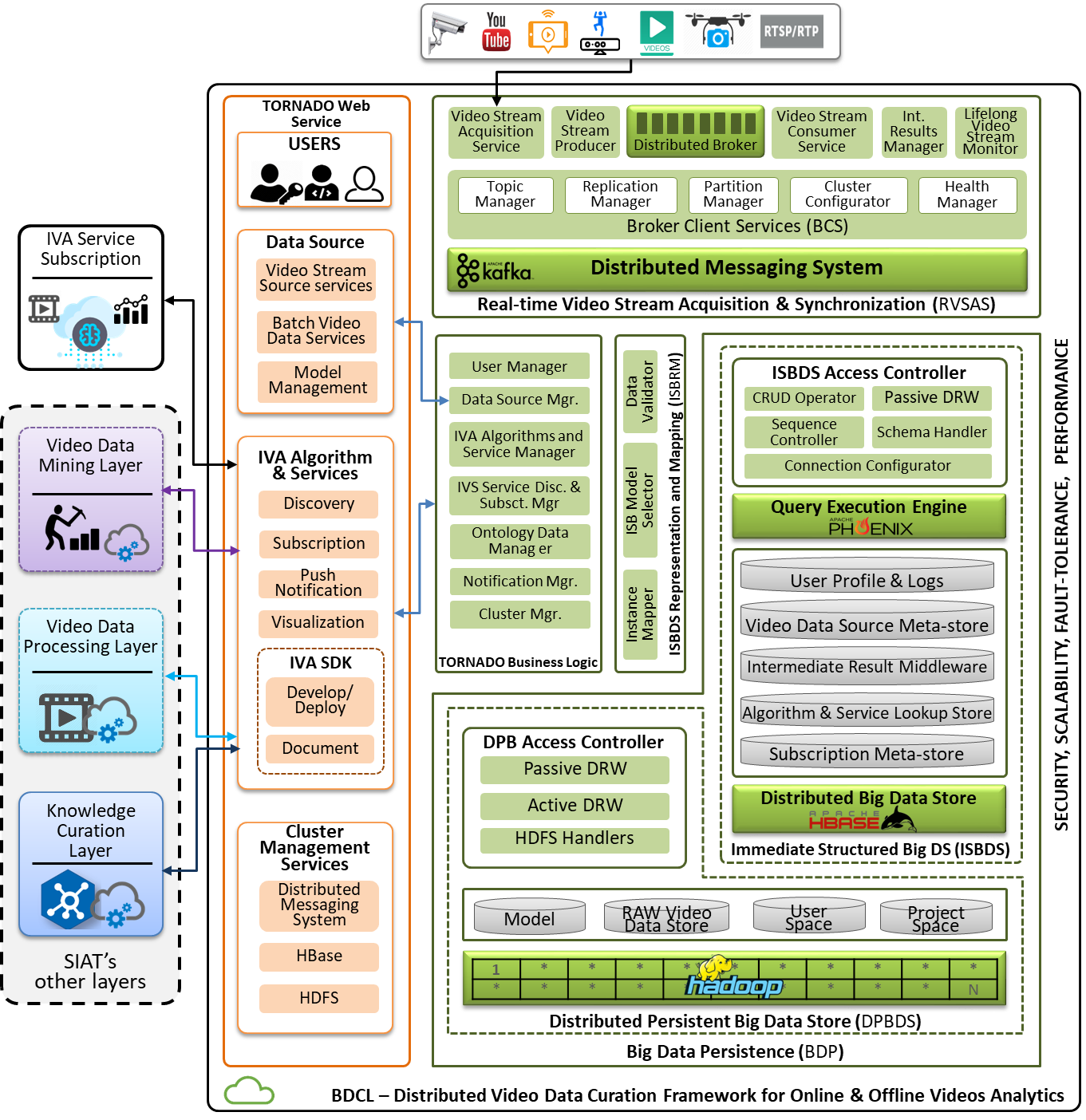
Figure 1: Proposed BDCL framework architecture.
BDCL Framework
As illustrated in Figure 3, BDCL is composed of six components, i.e., Real-time Video Stream Acquisition and Synchronization (RVSAS), Immediate Structured Big Data Store (ISBDS), Distributed Persistent Big Data Storage (DPBDS), ISBDS Representation and Mapping (ISBRM), BDCL Business Logic, and BDCL Web Services.
Real-time Video Stream Acquisition and Synchronization (RVSAS)
The RVSAS component provides interfaces and acquires large-scale video streams from device-independent video stream sources for on-the-fly processing. The video stream sources are synchronized based upon the user identification and the timestamp of the video stream generation. Then, it is queued in the form of mini-batches in distributed stream buffer for RIVA. The RIVA may vary in the context of a business domain, cross-linked with the video stream sources and user�s profile. RIVA services are deployed in a cluster of computers for distributed video stream processing to extract the value for contextual decision making. The video stream queued in the form of a mini-batch can be accessed while using Video Stream Consumer Services (VSCS). During RIVA service pipelining, the IR is maintained through Intermediate ResultsManager (IR-Manager). Similarly, RVSAS is equipped with a Lifelong Video Stream Monitor (LVSM) to provide a push-based notification response to the client with the help of a publish-subscribe mechanism. The extracted values (features and anomalies) and the actual video streams are then persisted into ISBDS and DPBDS, respectively.
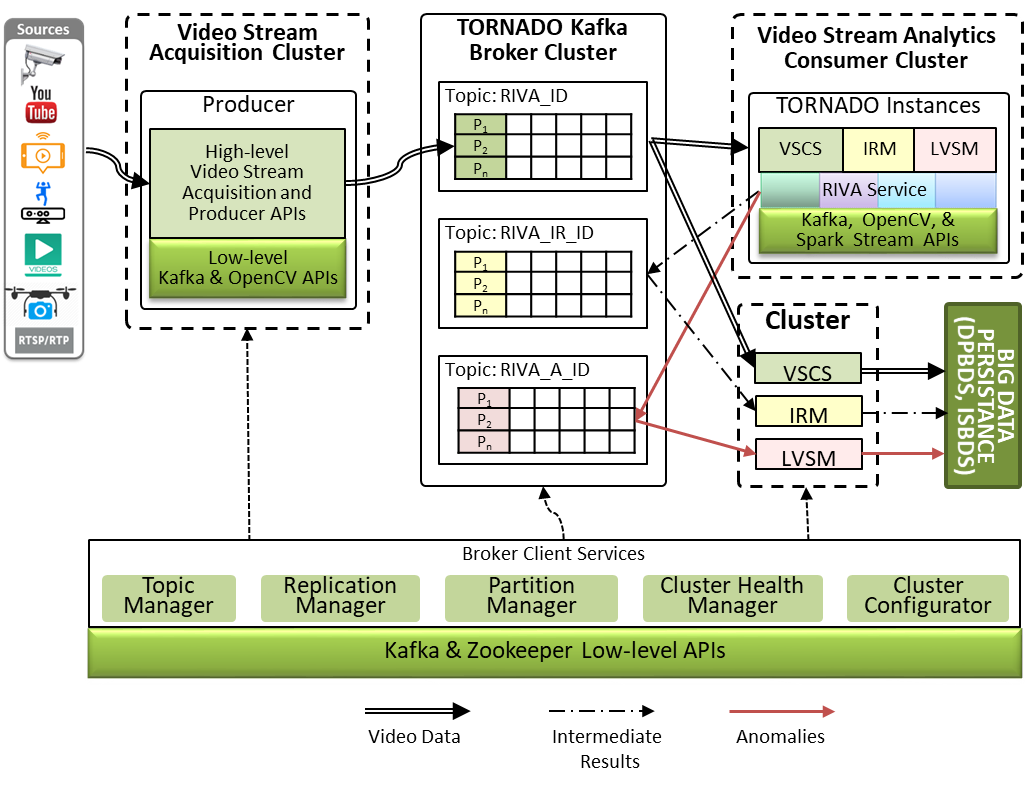
Figure 2: Video Stream Acquisition and Synchronization workflow
Immediate Structured Big Data Store (ISBDS)
ISBDS component is responsible for storing and managing large-scale structured data in a distributed environment according to the business logic implemented by BDCL Business Logic. The structured data is related to users, access rights, VDPL, VDML, KCL, metadata of the video data stream sources, batch datasets, big models, and service subscription information. This module also orchestrates the IR and anomalies being generated by a domain-specific IVA service. According to the demands of BDCL, two types of operations are required to be performed on the ISBDS, i.e., random read-write operation against the real-time queries and bulk load and store operations for offline analytics. For such operations, we develop and deploy ISBDS Access Controller to access the underlying data securely against random and scan read-write operations. The IDBDS data model is shown in the following figure.
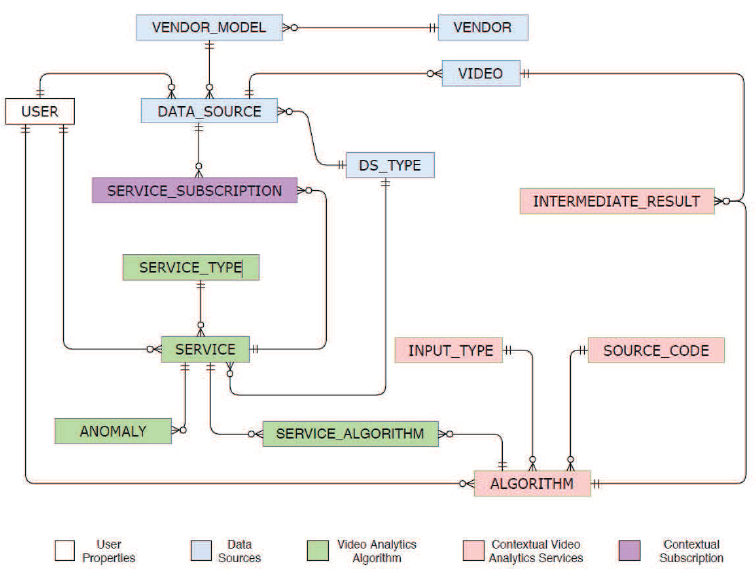
Figure 3: Immediate Structured Big data store model.
Distributed Persistent Big Data Storage (DPBDS)
DPBDS is built on top of the Hadoop Distributed File System (HDFS) and is responsible for providing permanent and distributed big data persistence to the raw video data, big models, and also supposed to maintain the actual IVA plugins deployed by other layers. During the contextual distributed offline video analytics, batch video data and models are needed to be loaded. Similarly, different HDFS file operations are required, for example, access permission, and file creation. In this context, we exploit the services of DPBDS Access Controller. In HDFS, under each User Space, three types of distributed directories are created, i.e., Raw Video Space, Model Space, and Project Space, as shown in the following figure.
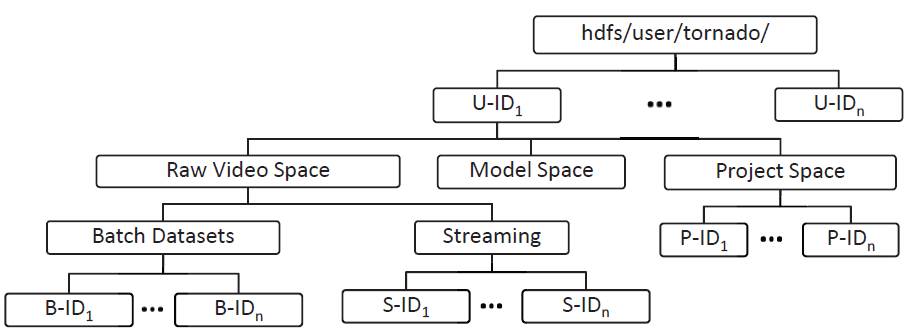
Figure 4: Realization of the hierarchical structure of user space in the Hadoop Distributed File System.
ISBDS Representation and Mapping (ISBRM)
The ISBRM component is responsible for validating and mapping the contextual data to the respective data stores according to the business logic of BDCL.
BDCL Business Logic
The BDCL Business Logic is subject to extendibility depending upon the future requirements. However, the current release implements and provide six types of modules, i.e., User Manager, Source Manager, IVA Algorithm and Service Manager, IVA Service Discovery and Subscription Manager, Ontology Data Manager, and Notification Manager. The user roles and access rights are shown in the following figure.
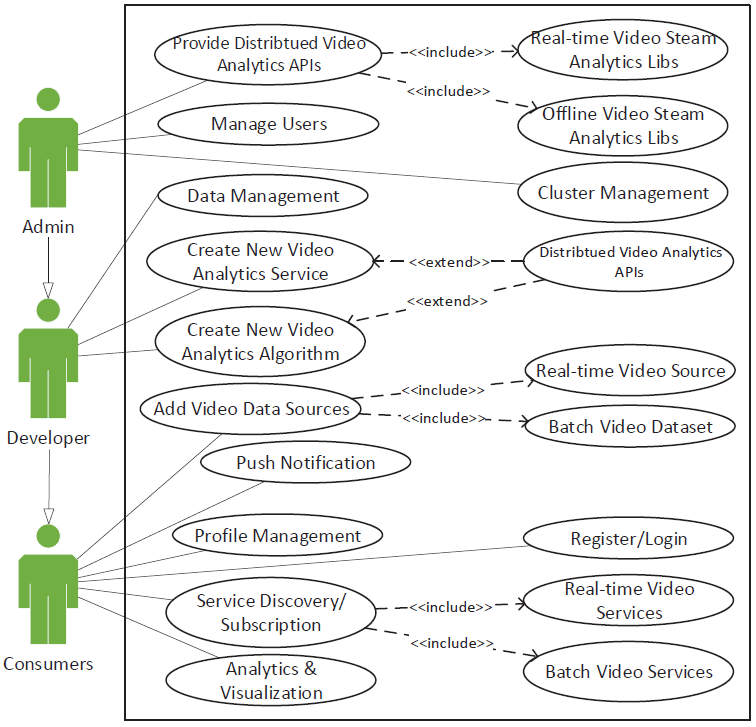
Figure 5: user roles and use case diagram.
BDCL Web Services
The BDCL is built to provide IVAAaaS and IVAaaS over the Web. Thus, we develop BDCL Web Services on top of BDCL Business Logic to allow the users to utilize the functionality of the proposed framework over the Web. Further technical details of each component are described in the following subsections.
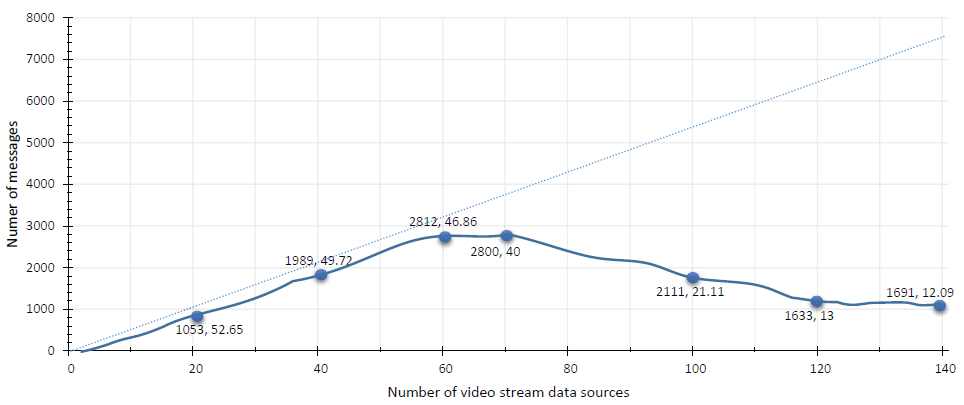
Figure 6: Stress testing of scalability of VSAS and VSP.
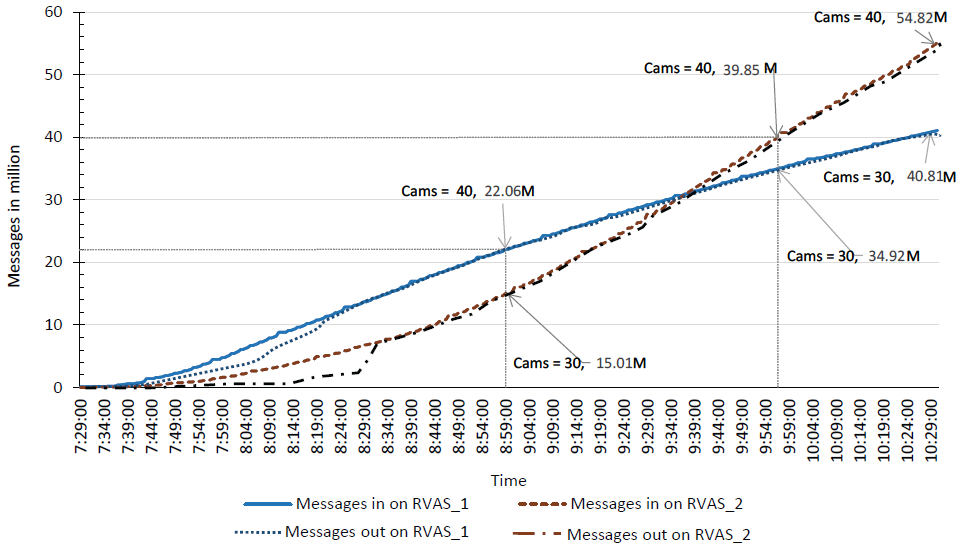
Figure 7: VSAS and VSP performance in production environment.
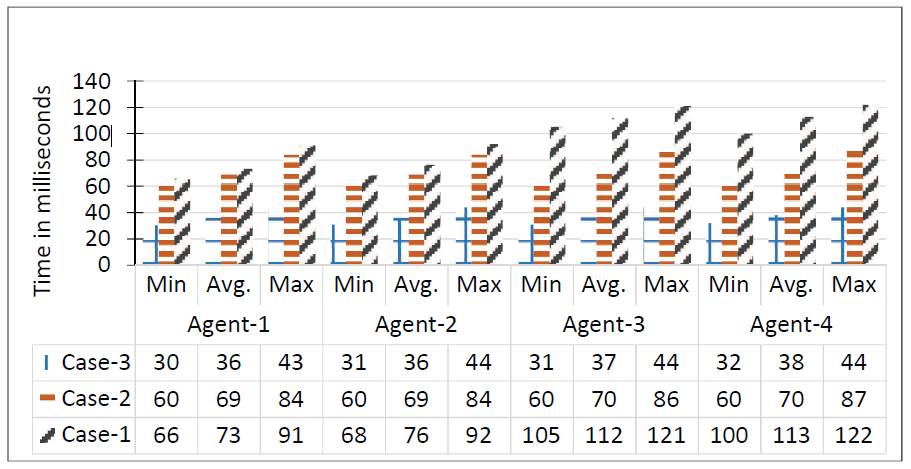
Figure 8: Notification delay performance evaluation.
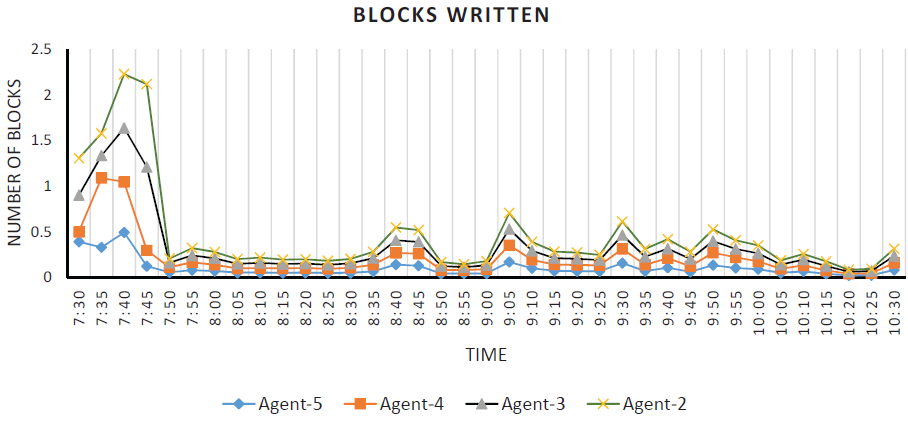
Figure 9: Performance of Distributed Persistent Big Data Store (Active Data Writer).
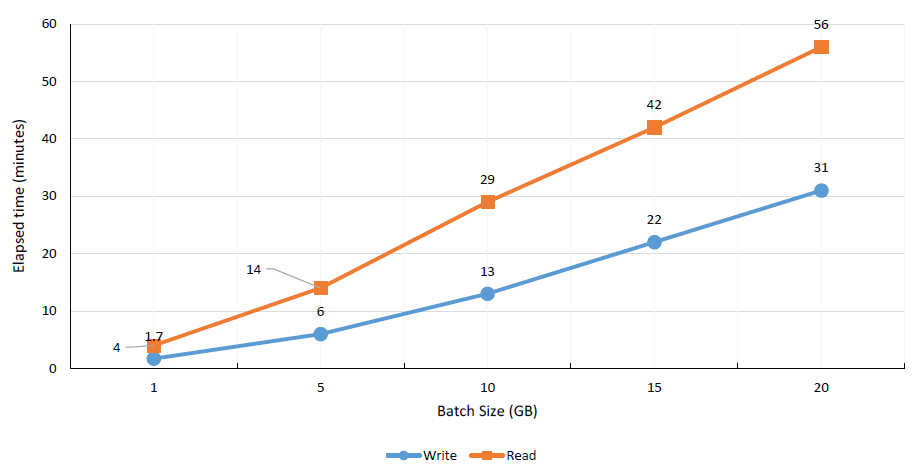
Figure 10: Performance evaluation of Passive Data Reader and Writer.
Cite As
Alam, Aftab, and Young-Koo Lee. "TORNADO: intermediate results orchestration based service-oriented data curation framework for intelligent video big data analytics in the cloud." Sensors 20.12 (2020): 3581.